The Right Fix for Expensive AEP Segments: Move the Math Upstream
A follow-up on our batch segmentation investigation — and the architectural pattern that eliminates the problem at its source.
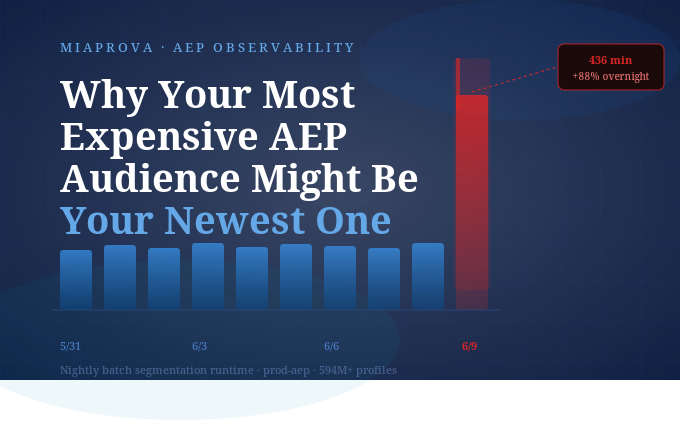
In our last post, we walked through how a single newly published audience caused a large retailer’s nightly AEP batch segmentation job to run for 7.3 hours instead of 3.5. The likely culprit was a segment that combined a 720-day purchase history scan, a multi-entity product lookup join, and a sum aggregation — all executed at query time, for millions of profiles, every single night.
When we shared those findings with the client, their response was exactly what you’d hope for from a sophisticated enterprise team. They already knew. And they were already fixing it.
“This is great perspective to have,” they told us. “Unfortunately, this isn’t an uncommon approach to targeting in the addressable channel space. We’re combatting this by pulling aggregation for transactions across different product groups upstream and applying it as an attribute on the profile. We’re in the QA phase on this data now and are hoping to implement later this year.”
That response is worth unpacking because what they’re describing is one of the most important architectural patterns in enterprise CDP practice, and it’s the correct long-term answer to a class of performance problems that affects almost every mature AEP deployment.
What “Pulling Aggregation Upstream” Actually Means
To understand the fix, you need to understand what made the original segment expensive in the first place.
The segment was asking AEP’s batch engine a complex question at query time: has this profile spent at least $150 on a specific product hierarchy in the last 720 days? To answer that question for a single profile, AEP had to retrieve two years of purchase events, join each event to a product lookup dataset to verify the hierarchy, filter down to matching records, sum the sale prices, and compare the result to the threshold.
That sequence is computationally expensive for one profile. Multiplied across seven million profiles in the base audience, run every night, it becomes a batch job that doubles in runtime.
The upstream pre-aggregation pattern breaks this cycle by separating when the math happens from when the segment runs.
Instead of asking AEP to compute the answer at segment evaluation time, an upstream pipeline — running on a schedule, with direct access to the full transaction history — computes the answer in advance for every profile. The result gets written back to the profile as a simple attribute:
profile.computed.product_hierarchy_spend_l2y = $187.50The nightly segment then becomes a single field comparison:
profile.computed.product_hierarchy_spend_l2y >= 150AEP reads one value. No event scan. No lookup join. No aggregation. The computation that previously took hours of batch time now takes milliseconds per profile.
This is the fundamental tradeoff: you move expensive, repeated computation out of the segmentation layer and into a dedicated pipeline that runs it once, efficiently, and stores the result where it can be reused cheaply.

Why “Different Product Groups” Is the Important Part
The detail in their response that signals mature thinking is the phrase “across different product groups.” They are not building a one-off fix for the specific segment that caused last week’s spike. They are building a generalized framework.
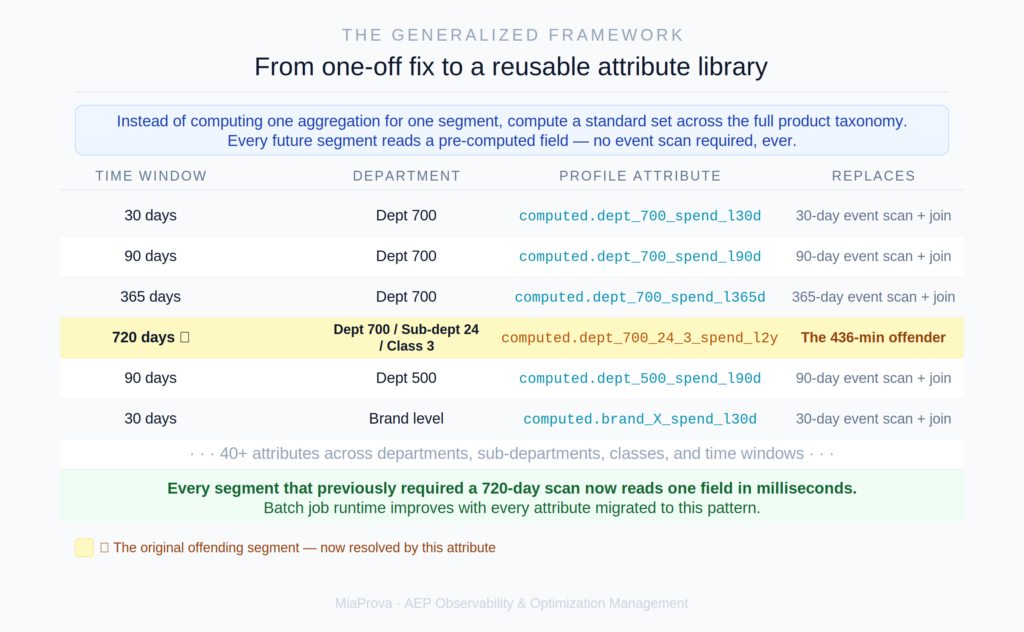
A naive approach would be to create a pre-computed attribute for this one segment’s product hierarchy — department 700, sub-department 24, class 3, 720-day window. That solves today’s problem but creates a new one: every future segment that needs purchase aggregation across a different product group requires its own new attribute, its own pipeline, and its own maintenance burden.
The smarter approach, which is what they appear to be doing, is to define a standard set of aggregations across the product taxonomy — by department, by sub-department, by class, by brand, perhaps at multiple time windows — and compute all of them in a single pipeline run. The result is a library of pre-computed spend attributes that any segment builder can use without triggering a new event scan.
profile.computed.dept_700_spend_l30d = $45.00
profile.computed.dept_700_spend_l90d = $112.00
profile.computed.dept_700_spend_l365d = $187.50
profile.computed.dept_700_spend_l720d = $312.00
profile.computed.dept_500_spend_l90d = $67.00
... and so on across the product hierarchyEvery segment that would previously have required a 720-day event scan and a multi-entity join now reads a pre-computed field. The batch job gets faster with every attribute that gets migrated to this pattern, not slower with every new segment that gets built.
The Architecture Behind the Pattern
The “upstream pipeline” they reference is almost certainly a purpose-built data processing job running outside of AEP — likely on Databricks, Spark, or a similar compute framework with direct access to the full transaction history. The workflow looks roughly like this:
A scheduled job pulls the raw transaction data from its source, which might be a data warehouse, a raw dataset in AEP’s data lake, or a direct feed from the point-of-sale system. It applies the aggregation logic — grouping by profile identity, filtering by product hierarchy, summing sale amounts, computing values at each lookback window. The results get written to a flat dataset where each row is a profile and each column is a pre-computed metric. That dataset gets ingested into AEP as a profile attribute dataset on a daily schedule, updating the values on each profile before the nightly batch segmentation job runs.
The segmentation job then finds fresh, pre-computed values already sitting on each profile and reads them directly. The event history never gets touched during segmentation.
The Tradeoff: Speed for Freshness
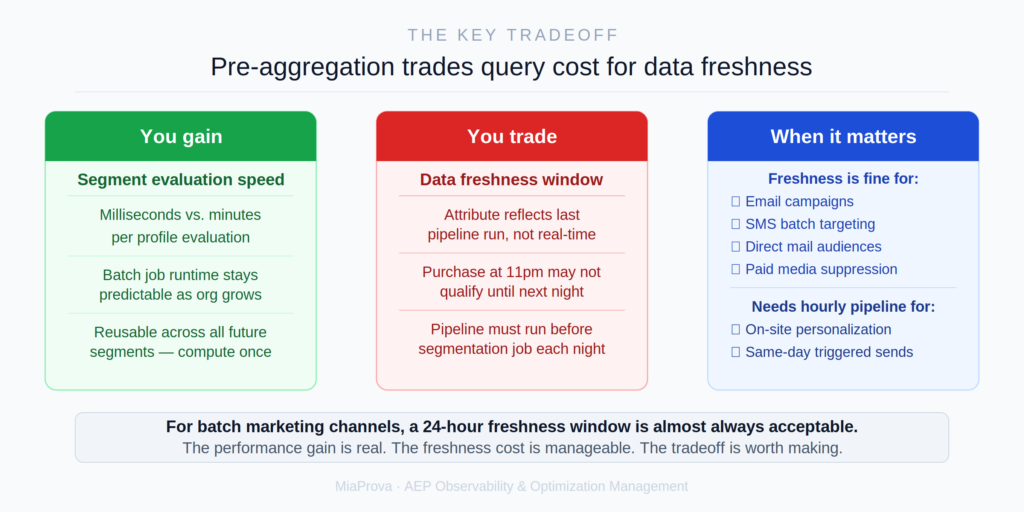
Pre-aggregated attributes are not free. They introduce a data freshness window that doesn’t exist with real-time event scans.
When a segment directly scans event history, it is always working with the most recent data in the profile store. A purchase made at 11pm will be reflected in a midnight batch job. When a segment reads a pre-computed attribute, it is working with data that is as fresh as the last pipeline run. If the aggregation pipeline runs at 10pm and the batch segmentation job runs at midnight, a purchase made at 11pm won’t be reflected until tomorrow night’s pipeline run updates the attribute.
For most marketing use cases — email campaigns, SMS targeting, direct mail — a 24-hour freshness window is completely acceptable. The commercial decision to target someone based on their spend history is rarely so time-sensitive that a one-day lag matters.
Where it does matter is in real-time or near-real-time personalization scenarios: website recommendations, triggered messaging, next-best-action decisions that need to respond to behavior from earlier the same day. For those use cases, the pre-aggregation pattern needs to either run more frequently (hourly pipelines rather than daily) or be complemented by streaming computed attributes that update in real time.
The architecture teams building these systems make this tradeoff explicitly. The question is not whether to pre-aggregate, but at what frequency and for which use cases.
Adobe’s Native Answer: Computed Attributes
It is worth noting that AEP has a native feature designed for exactly this pattern. Computed Attributes — available in the Real-Time CDP product — allow you to define aggregations over profile event data and have AEP maintain running values that are exposed as profile fields. You define the logic once in the AEP interface, and the platform keeps the attribute current on an ongoing basis without requiring a separate external pipeline.
The fact that a mature enterprise team is building their own upstream aggregation pipeline rather than using native Computed Attributes is instructive. It suggests one or more of the following is true for their implementation: the product hierarchy complexity or the lookback window length exceeds what native Computed Attributes handles efficiently, they have an existing data infrastructure investment (Databricks appears throughout their pipeline data) that makes the upstream approach more practical, they need tighter control over the computation logic or the ingestion schedule than the native feature allows, or the cost model for their AEP contract makes the native feature less attractive than running compute externally.
None of these are criticisms — they are architectural realities for large enterprises. Native Computed Attributes are genuinely useful and worth evaluating for teams that don’t have the data engineering capacity to build and maintain external pipelines. The important thing is that both paths lead to the same result: expensive event scan logic gets moved out of the segmentation layer.
What This Means for Segment Builders
If you are building audience definitions in AEP Segment Builder and you find yourself constructing logic that involves purchase history aggregations, time-windowed spend calculations, or event count thresholds over long lookback windows, it is worth asking a question before you publish: is this computation already available as a profile attribute, or should it be?
The answer shapes not just your segment’s performance but the entire batch job’s runtime for every other audience in the org that runs alongside it.
A few signals that a segment definition is a candidate for the pre-aggregation pattern:
Any lookback window longer than 90 days combined with a sum or count aggregation is almost certainly better served by a pre-computed attribute. The event scan volume grows linearly with the window length, and the aggregation has to run from scratch every night regardless of whether the profile’s qualifying behavior has changed.
Multi-entity joins inside event logic are expensive even at short lookback windows. If your segment needs to filter events by attributes that live in a lookup dataset — product hierarchy, store attributes, category taxonomy — the join cost is real and recurring. Pre-computing the filtered aggregate and storing it as a profile attribute eliminates the join entirely at segment evaluation time.
Any aggregation that will be reused across multiple segments is a strong candidate. If three different segments all need some variant of “spent $X on product category Y in the last Z days,” that computation should run once in a pipeline and be read many times from a profile attribute, not recomputed independently in each segment.
The Broader Lesson
What this client is building is not a workaround. It is a data architecture pattern that scales where query-time aggregation does not. Every enterprise running a large segment inventory on a mature customer profile will eventually hit the same wall — and the teams that have thought about this pattern in advance are the ones whose batch jobs stay predictable as the business grows and the audience definitions get more sophisticated.
The nightly batch window is a shared resource. Every segment definition in your org competes for the same infrastructure during that window. A segment that scans two years of event history and joins to a lookup dataset for seven million profiles is not just slow for itself — it is slow for everyone else running alongside it.
Moving that computation upstream is not just a performance optimization. It is a form of operational citizenship for your AEP environment.
We’ll be tracking how this client’s implementation progresses — and what the impact looks like in MiaProva’s Daily Batch Job Monitor once the pre-aggregated attributes are live in production. That before-and-after comparison is a story worth telling.
MiaProva is an AEP observability, monitoring, and optimization management platform built for teams running Adobe Experience Platform at enterprise scale. Learn more at miaprova.com.